應用程式就緒 AI 模型
從掃描的文件、行動裝置上傳、PDF 等內容擷取文字
OCI 文件理解會使用光學字元辨識 (OCR) 及其他進階模型,自動從各種文件檔案 (包括旋轉、傾斜或有陰影的文件) 擷取文字,以因應費用處理與客戶導引時經常出現的品質問題。
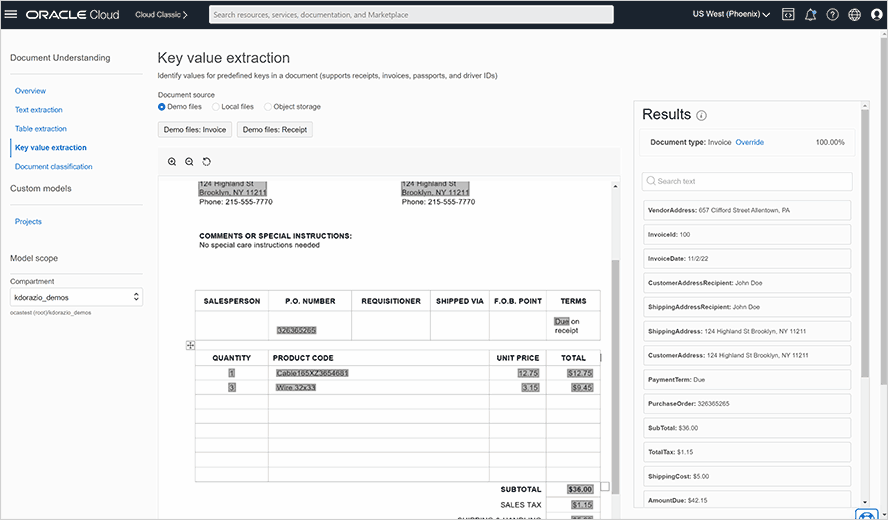
擷取文件中的表格和索引鍵欄位
自動識別並擷取文件中的表格結構,包括表格中的資料列與資料欄關係。針對費用和身分文件,OCI 文件理解可以識別發票、收據、護照、駕照和醫療保險卡,並從中擷取索引鍵值組。
將文件分類
識別文件並將其分類為通用類別,例如商業發票、收據及履歷。通用應用程式包括費用處理、增強搜尋與文件擷取。
多語言支援
OCI 文件理解的 OCR 和鍵值組預先訓練模型支援多種語言,包括阿拉伯文、中文、荷蘭文、英文、法文、德文、希伯來文、日文、葡萄牙文、俄文、西班牙文和烏克蘭文。
自訂模型
建立適用於金鑰值組和文件分類的自訂模型。客戶若使用 OCI 文件理解,就能以自己的資料來訓練、評估、部署和分析模型。
安全且可存取
專為安全和隱私而打造
為了維護客戶的隱私權,OCI 文件理解的模型不會儲存任何用於訓練、偵錯或其他用途的資料。
輕鬆部署
OCI 文件理解是一種多功能服務,可透過 REST API、多個 SDK (包括 Python 和 Java) 或 OCI 指令行加以呼叫。開發人員無需具備資料科學或機器學習專長,即可輕鬆部署可調整的文件服務。
專用端點
專用端點可提供更高的控制權,並能夠滿足 OCI 文件理解工作流程的高輸送量需求。