
概要
反復的なタスクを合理化したり、完全に自動化するために、AIの助けを借りないのはなぜですか? 基盤モデルを使用して反復的なタスクを自動化すると、魅力的に聞こえるかもしれませんが、機密データを危険にさらす可能性があります。取得拡張生成(RAG)は、モデルのコーパスから推論データを分離して微調整する代替手段です。
推論データとモデルを分離しておきたいのですが、どの大規模言語モデル(LLM)を使用するかの選択肢と、効率化のための強力なGPUも必要です。これを一つのGPUでやればいいのに!
このデモでは、単一のNVIDIA A10 GPU、LangChain、LlamaIndex、Qdrant、vLLMなどのオープン・ソース・フレームワーク、およびMistral AIからの70億パラメータLLMを使用してRAGソリューションをデプロイする方法を紹介します。価格とパフォーマンスのバランスが優れ、必要に応じてデータを更新しながら推論データを分離できます。
デモ
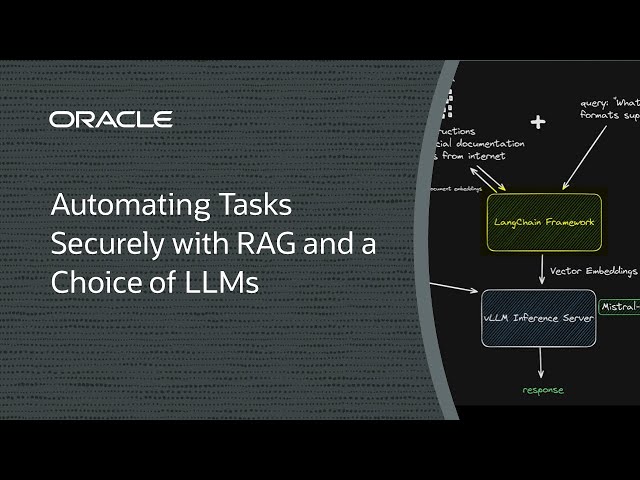
前提条件および設定
- Oracle Cloudアカウント—サインアップ・ページ
- Oracle GPUコンピュート・インスタンス—ドキュメンテーション
- LlamaIndex - ドキュメント
- LangChain—ドキュメント
- vLLM—ドキュメント
- Qdrant—ドキュメント