개요
반복 작업을 간소화하거나 완전히 자동화하려는 노력에서 AI의 도움을 청하지 않는 이유는 무엇입니까? 반복 작업을 자동화하는 기반 모델을 사용하면 매력적일 수 있지만 기밀 데이터를 위험에 빠뜨릴 수 있습니다. 검색 증강 생성(RAG)은 모델의 코퍼스에서 추론 데이터를 격리하여 미세 조정의 대안입니다.
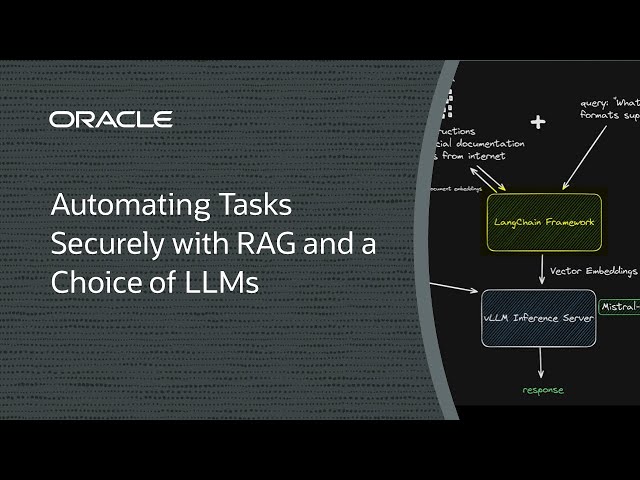
우리는 추론 데이터와 모델을 분리하고 싶지만, 우리가 사용하는 대규모 언어 모델(LLM)과 효율성을 위한 강력한 GPU를 선택하기를 원합니다. 이 모든 것을 하나의 GPU로 할 수 있다면 상상해보십시오!
이 데모에서는 단일 NVIDIA A10 GPU, LangChain, LlamaIndex, Qdrant 또는 vLLM과 같은 오픈 소스 프레임워크, Mistral AI의 가벼운 70억 매개변수 LLM을 사용하여 RAG 솔루션을 배포하는 방법을 소개합니다. 가격과 성능의 균형이 탁월하며 추론 데이터를 분리하고 필요에 따라 데이터를 업데이트합니다.
데모